Part 1: Synchronicity Everywhere
This is the first part of a multi-week series of posts describing various implementations of Command Query Responsibility Segregation (CQRS) and Event Sourcing using Dropwizard. CQRS is a design pattern where commands modifying data are separated from queries requesting it and the data is denormalized into structures matching the Data Transfer Objects (DTO) that these queries are requesting. I’m not going to get deep into the details of CQRS here, if you want to learn more then I highly recommend Martin Fowler’s blog post on the subject. But here is a quick comparison between CRUD (Create, Read, Update, Delete) and CQRS. A typical CRUD application looks like this:
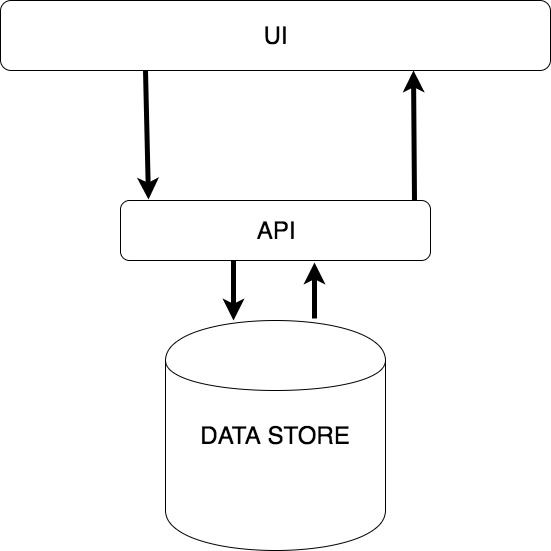
As you can see, there’s a User Interface which writes and request data from an API which in turn persists and retrieves it from a data store.
In contrast, here’s a basic CQRS application:

The major difference, as you can see, is that we are separating the source of truth written to by the api from the projection which is read by the api. A denormalizer is used to keep the two in sync. In future weeks we’ll introduce asynchronicity, message buses like Kafka, and eventual consistency. But for our initial purposes we will assume that this denormalization will be done synchronously with the update of the source of truth and prior to the response being sent to the user interface.
I’ve created a small Dropwizard application to demonstrate this pattern using Mongo. You can find the code and instructions on how to run it in IntelliJ and send commands to it via Postman here.
The steps for a data update request (command) are:
- Http request is received by API to change entity
- Request is translated to command(s)
- Command(s) are handled
- Existing entity is retrieved and command(s) are validated
- Command(s) are applied to entity and delta is determined
- If there’s a delta:
- The entity is updated
- Event(s) are generated
- If the Command results in Event(s):
- The event(s) are denormalized to relevant data sources
- Response is sent to client
And the steps for a data retrieval request (query) are:
- Http request is made to retrieve entity
- Entity is retrieved via key lookup
As you can see, data changes require a few extra steps but data retrieval is extremely simple. This would still be the case regardless of how many sources of truth must be denormalized and combined to form the document we need for the query.
However there are still some drawbacks:
- Duplicate data storage
- Transactions across data stores need to be handled by application
- Denormalization needs to be carefully managed to avoid inconsistent states
- Writes are slower/more expensive since we are synchronously denormalizing
- Reads can result in large payloads depending on domain design
However, in some cases these are outweighed by the benefits:
- Reads are faster and can be optimized separately from writes
- Since data is stored as key/value, lower level/cheaper data storage can be used
- Fewer http calls on read since documents are integrated on writes
- UX doesn’t need to change because consistency model is the same
- We don’t need message buses (yet!)
Coming up in part 2: CQRS with asynchronous commands